
 当前位置:
当前位置: 新闻资讯
新闻 | 我院赵天成博士OmLab团队斩获计算机视觉国际顶会ECCV 2022 挑战赛双料冠军


日前,浙江大学滨江研究院Om人工智能研究中心主任兼研究员赵天成博士团队OmLab在国际顶会ECCV 2022 ODinW 挑战赛中获得 Full-Shot(全量数据学习)赛道与Few-Shot(小样本数据学习)赛道双料冠军、在 Zero-Shot 赛道获得第四排名的佳绩。基于全新目标检测框架OmDet的先进性和创新价值,赵天成博士受邀发表主题报告演讲。

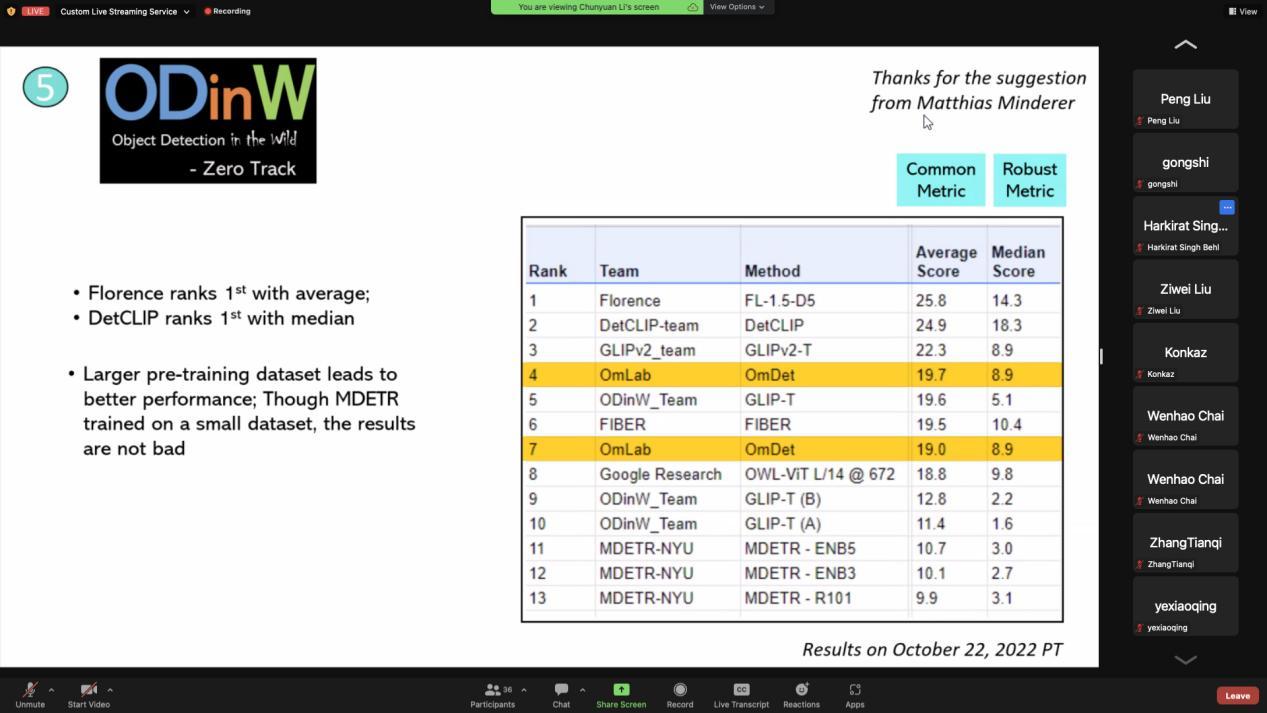
ECCV(European Conference on Computer Vision,欧洲计算机视觉国际会议)是计算机视觉方向的世界范围三大顶级会议之一。本次ODinW(Object Detection in the Wild,开放域目标检测)挑战赛由微软主办,旨在验证大模型在不同领域数据上的能力。
基于OmDet框架的先进性和相关研究的创新价值,赵天成博士受邀参与Spotlight Sessions,并发表《OmDet: Language-Aware Object Detection with Large-scale Vision-Language Multi-dataset Pre-training》报告演讲,受到广泛关注。


目标检测(Object Detection,OD)是机器视觉领域任务的重要手段,广泛应用智能视频监控、工业检测、机器人视觉等场景,AI视觉技术在学术、产业等不同领域热度空前,同样创新难度也在不断加大。经典的OD研究专注于改进检测器网络,以使用固定输出标签集(例如COCO中的80个类)实现更高的准确度和更低的延迟,OmLab团队提出的一种基于VLP(视觉语言预训练)的全新目标检测框架:OmDet,探索一种持续学习的方法,即检测器能否从许多视觉词汇量增加的OD数据集中逐步学习,并最终实现开放词汇检测能力。
OmDet在COCO、Pascal VOC、Wider Face和Wider Pedestrian四个OD 数据集中的实验结果表明,OmDet不仅能够从所有数据集中学习而不会出现标签冲突,而且由于其在任务之间的知识共享,它比单个数据集检测器具有更强的性能。
在此基础上,OmLab团队进行了更大规模的研究,将OmDet扩展到非常大的词汇预训练,使用混合了2000万张图像和400万个独特文本标签的OD数据集进行预训练,其中包括人工标注和伪标签。得到的模型在最近提出的ODinW数据集上进行评估,该数据集涵盖了各个领域的35个不同的OD任务。
实验表明,通过多数据集预训练扩大词汇量可有效提高零/少样本学习和参数效率微调。OmDet在一系列不同的下游任务上实现了最先进的性能。未来可以通过有效的任务采样策略改进OmDet,利用更多样化的多模态数据集,探索不同的语言和视觉 Backbone(骨干网络),冻结特定参数或完全更新它们。
机器视觉2.0在多项国际顶会竞赛中获得肯定,团队依托技术优势不断探索创新、加速能力突破,通过优化升级在预训练大模型等领域的核心能力,自研产品体系与开放平台并实现快速落地应用,更好地助力各行各业实现降本增效,推动数字技术与实体经济加速融合。
